My Journey into Scalable WebRTC with Mediasoup
A few days ago, a friend showed me a project — a simple Zoom clone built with WebRTC.
It was impressive at first glance: two users connecting face-to-face in real time.
But when I looked deeper, I realized one thing: it wouldn’t scale.
That sparked an idea. What if I could take the same concept — but rebuild it the way real, production-grade video apps like Zoom or Google Meet actually work?
That’s how Project Hyperion was born: a learning experiment in building scalable real-time systems.
💡 Why Scaling WebRTC Is Hard
WebRTC (the technology behind most video calls) connects users directly — known as peer-to-peer (P2P).
This works fine for two or three people. But with more participants, it quickly collapses.
Imagine 10 people in a call.
Each must upload their video to 9 others, resulting in 81 connections total.
Bandwidth gets crushed. CPUs melt. Everyone lags.
This is known as the N² problem — and it’s why “simple” video apps don’t scale.
📊 Visualizing the Problem
Here’s how the three major real-time architectures compare:
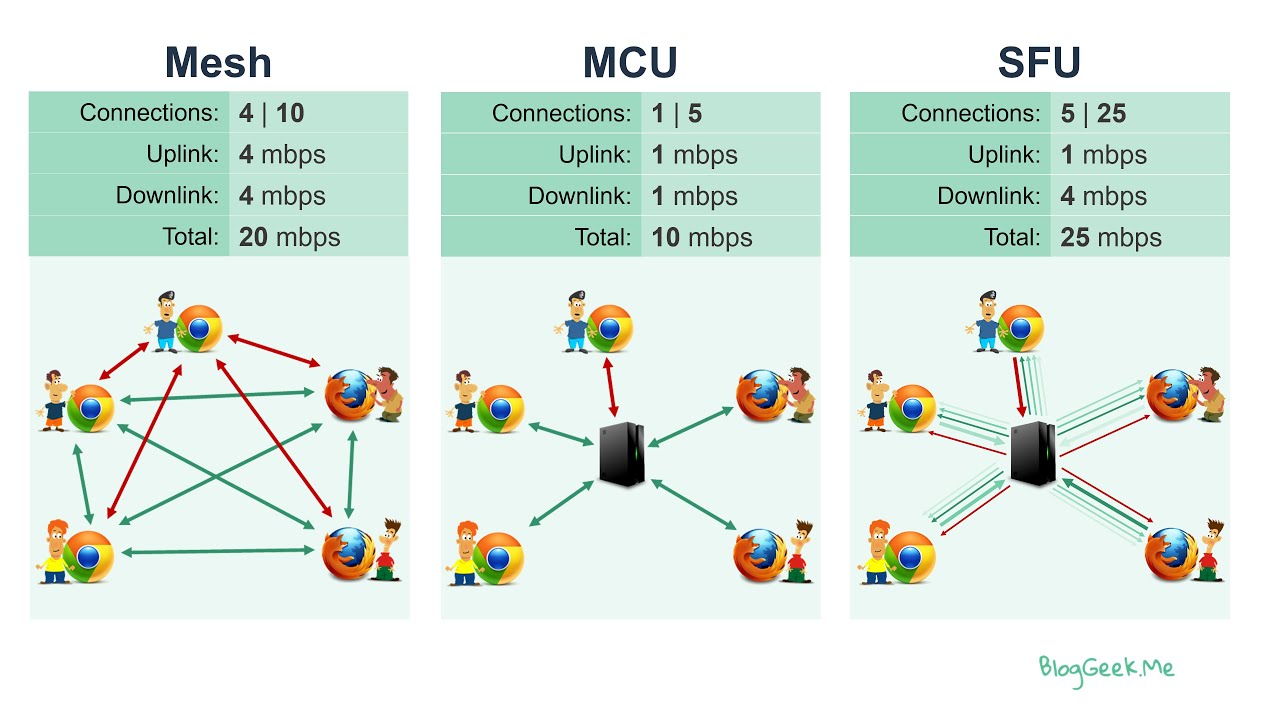 P2P (mesh) scales poorly, MCU is expensive to run, and SFU offers the best balance between scalability and cost.
P2P (mesh) scales poorly, MCU is expensive to run, and SFU offers the best balance between scalability and cost.
That’s why I adopted an SFU (Selective Forwarding Unit) architecture.
Instead of everyone sending video to everyone else, each user uploads one stream to a central server — and the SFU redistributes it to others.
Efficient, simple, and scalable.
⚙️ The Architecture
To make this system both scalable and fault-tolerant, I used a mix of distributed tools:
- Mediasoup for handling all audio/video streams
- Kafka to coordinate multiple signaling servers
- Redis for fast in-memory state management
- Docker Compose for managing the entire environment
- Nginx as a load balancer
- Electron for the client app
Here’s the architecture visualization:
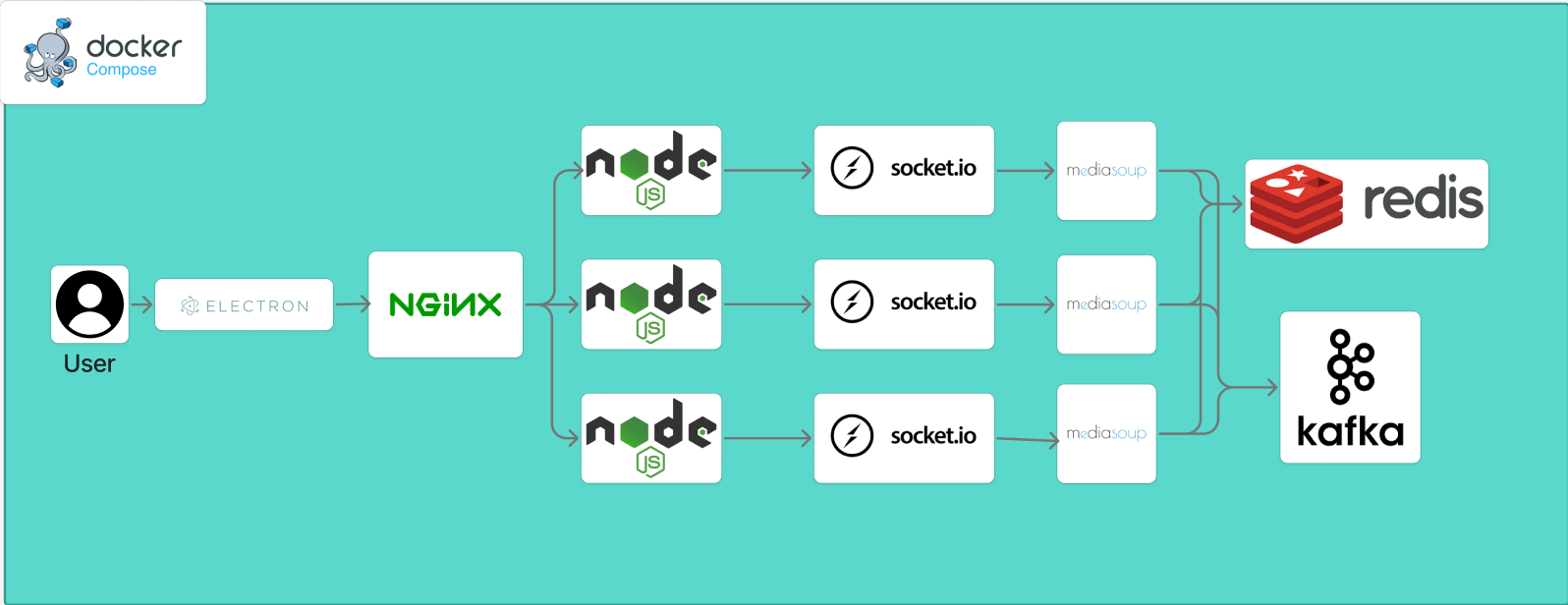 A horizontally scalable system where multiple Node.js servers handle signaling, backed by Redis and Kafka.
A horizontally scalable system where multiple Node.js servers handle signaling, backed by Redis and Kafka.
🧠 What I Learned
- Scaling isn’t just about adding more servers — it’s about decoupling systems.
- Kafka allows multiple backend servers to “talk” to each other instantly.
- Redis keeps real-time state synced between them.
- Mediasoup is powerful, but understanding transports, producers, and consumers is key.
- Docker made running everything in isolated containers effortless.
🧩 The Stack
| Purpose | Technology |
|---|---|
| Client | Electron (Desktop) |
| Real-Time Media | WebRTC + Mediasoup |
| Signaling | Node.js + Socket.IO |
| Message Broker | Apache Kafka |
| Cache / State | Redis |
| Load Balancer | Nginx |
| Environment | Docker Compose |
🔮 What’s Next
Next up, I plan to test multi-instance scaling — running multiple SFUs and distributing users across them automatically.
After that: adding chat, screen sharing, and perhaps even real-time analytics.
This isn’t about cloning Zoom.
It’s about understanding how Zoom could be built — from the ground up.
🛰️ GitHub Repository:
https://github.com/NeurologiaLogic/scalable-zoom-clone